引言
近年来,大语言模型(Large Language Models, LLM)的快速发展彻底改变了自然语言处理(NLP)领域。从 GPT-3 到 ChatGPT,再到 Claude 和 Llama,这些模型展现出了惊人的语言理解和生成能力。本文将深入探讨 LLM 的核心技术原理,帮助你理解这些"智能"背后的秘密。
什么是大语言模型?
大语言模型是一种基于深度学习的神经网络模型,通过在海量文本数据上进行训练,学习语言的统计规律和语义关系。它们的"大"体现在三个方面:
- 参数规模:从数十亿到数千亿参数
- 训练数据:TB 级别的文本语料库
- 计算资源:需要数千块 GPU 训练数月
LLM 的核心能力
- ✅ 文本生成:写文章、代码、诗歌等
- ✅ 问答系统:回答各类问题
- ✅ 翻译:多语言互译
- ✅ 摘要:提炼长文要点
- ✅ 推理:逻辑推理和常识判断
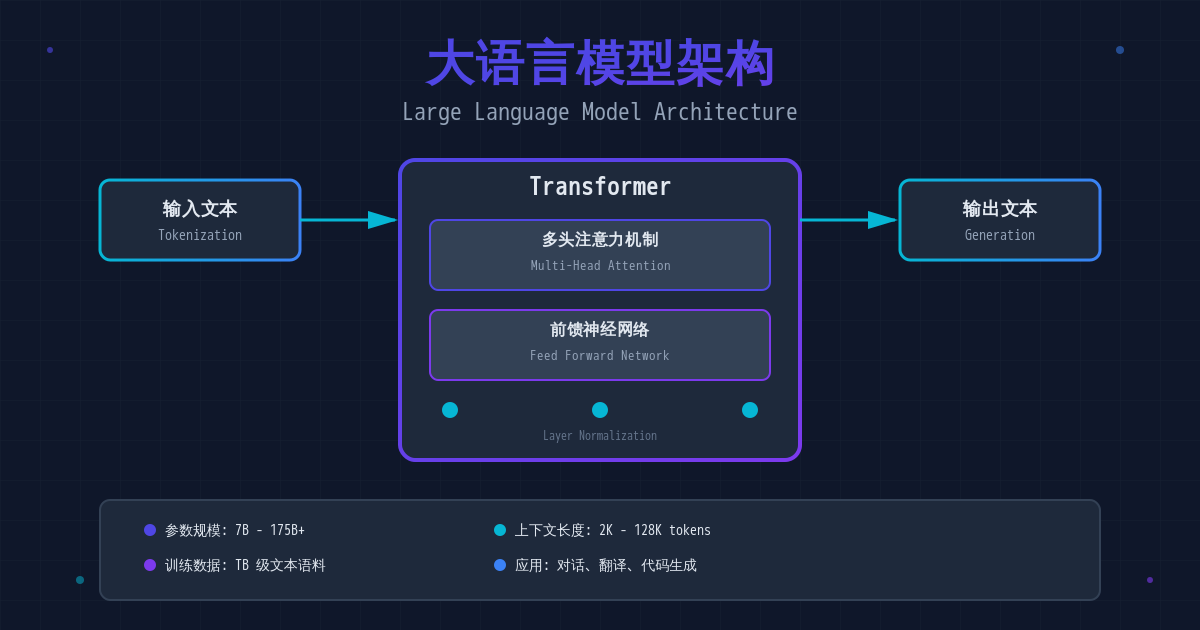
Transformer:LLM 的基石
注意力机制(Attention Mechanism)
Transformer 架构的核心是自注意力机制(Self-Attention),它允许模型在处理每个词时,关注整个句子中所有其他词的信息。
# 简化的自注意力计算
def self_attention(Q, K, V):
"""
Q: Query 矩阵
K: Key 矩阵
V: Value 矩阵
"""
# 计算注意力分数
scores = Q @ K.T / sqrt(d_k)
# Softmax 归一化
attention_weights = softmax(scores)
# 加权求和
output = attention_weights @ V
return output
多头注意力(Multi-Head Attention)
为了让模型从多个角度理解文本,Transformer 使用了多头注意力机制:
输入文本 → [Head 1, Head 2, ..., Head 8] → 拼接 → 线性变换 → 输出
每个"头"学习不同的语义关系,例如:
- Head 1:主谓关系
- Head 2:修饰关系
- Head 3:时间关系
GPT 系列的演进
GPT-1(2018)
- 参数量:1.17 亿
- 创新点:无监督预训练 + 有监督微调
- 影响:证明了预训练的有效性
GPT-2(2019)
- 参数量:15 亿
- 突破:Zero-shot 学习能力
- 争议:因"过于危险"延迟发布完整模型
GPT-3(2020)
- 参数量:1750 亿
- 能力飞跃:
- Few-shot Learning(少样本学习)
- In-context Learning(上下文学习)
- 涌现能力(Emergent Abilities)
ChatGPT(2022)
基于 GPT-3.5/GPT-4,通过以下技术优化:
RLHF(Reinforcement Learning from Human Feedback)
- 人类反馈强化学习
- 使输出更符合人类偏好
指令微调(Instruction Tuning)
- 训练模型遵循指令
- 提升对话交互能力
LLM 的训练流程
1. 预训练阶段(Pre-training)
graph LR
A[海量文本数据] --> B[Tokenization]
B --> C[Next Token Prediction]
C --> D[反向传播更新参数]
D --> E[重复数百万次]
目标:预测下一个词
# 训练目标函数
loss = CrossEntropy(predicted_token, actual_token)
2. 微调阶段(Fine-tuning)
- 监督微调(SFT):在特定任务数据上训练
- RLHF:基于人类反馈优化
- 对齐(Alignment):确保安全性和有用性
提示工程(Prompt Engineering)
有效使用 LLM 的关键在于设计好的提示词:
❌ 糟糕的提示
写一篇文章
✅ 优秀的提示
请以技术博客的风格,写一篇 800 字左右的文章,
主题是"如何优化 Python 程序性能"。
要求:
1. 包含具体代码示例
2. 面向中级开发者
3. 结构清晰,分点论述
4. 使用专业但易懂的语言
提示技巧
- 🎯 明确角色:
你是一位资深 Python 开发者... - 📝 具体要求:字数、格式、风格
- 💡 提供示例:Few-shot Learning
- 🔄 迭代优化:根据输出调整提示
LLM 的局限性
尽管强大,LLM 仍存在诸多限制:
1. 幻觉问题(Hallucination)
模型可能生成看似合理但实际错误的内容:
问:法国的首都是哪里?
错误回答:法国的首都是马赛(应该是巴黎)
2. 知识截止日期
训练数据有时间限制,无法获取最新信息。
3. 数学推理能力弱
对于复杂计算和逻辑推理,准确率较低。
4. 偏见问题
训练数据中的偏见会被模型学习和放大。
开源 LLM 生态
Llama 2(Meta)
- 特点:完全开源,商业友好
- 规模:7B、13B、70B 参数
- 应用:可本地部署
Mistral 7B
- 亮点:性能媲美 Llama 2 13B
- 优势:模型更小,推理更快
ChatGLM(清华)
- 定位:中文优化
- 特色:支持超长上下文(128K tokens)
实践建议
1. 选择合适的模型
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 原型开发 | GPT-3.5 | 快速、便宜 |
| 生产应用 | GPT-4 | 性能最强 |
| 本地部署 | Llama 2 7B | 开源、资源需求低 |
| 中文应用 | ChatGLM | 中文性能优秀 |
2. 成本优化
- 使用缓存减少重复调用
- 批处理多个请求
- 选择合适的上下文长度
- 考虑开源替代方案
3. 安全性考虑
- ⚠️ 输入验证:防止提示注入攻击
- ⚠️ 输出过滤:检查敏感内容
- ⚠️ 隐私保护:避免发送敏感数据
- ⚠️ 审核机制:人工审查关键输出
未来展望
多模态模型
GPT-4V、Gemini 等已支持:
- 🖼️ 图像理解
- 🎵 音频处理
- 🎬 视频分析
Agent 系统
LLM + 工具使用 = 智能代理:
# LLM Agent 伪代码
class LLMAgent:
def __init__(self):
self.llm = GPT4()
self.tools = [Calculator(), WebSearch(), CodeRunner()]
def solve_task(self, task):
plan = self.llm.plan(task)
for step in plan:
tool = self.select_tool(step)
result = tool.execute(step)
return self.llm.summarize(results)
领域专用模型
- 医疗:Med-PaLM
- 法律:LegalBERT
- 金融:BloombergGPT
- 代码:CodeLlama、StarCoder
结论
大语言模型代表了人工智能的重大突破,它们不仅改变了我们与计算机交互的方式,也为无数应用场景提供了新的可能性。理解 LLM 的工作原理,掌握有效使用它们的方法,将成为未来开发者的必备技能。
虽然当前的 LLM 还存在诸多限制,但随着技术的不断进步,我们有理由相信,更强大、更安全、更可控的语言模型终将到来。
参考资料
- Attention Is All You Need - Transformer 原论文
- GPT-3 Paper - OpenAI GPT-3 技术报告
- LLaMA: Open and Efficient Foundation Language Models
- OpenAI API Documentation
- Hugging Face Transformers
💬 讨论:你认为 LLM 最有潜力的应用场景是什么?欢迎在评论区分享你的想法!